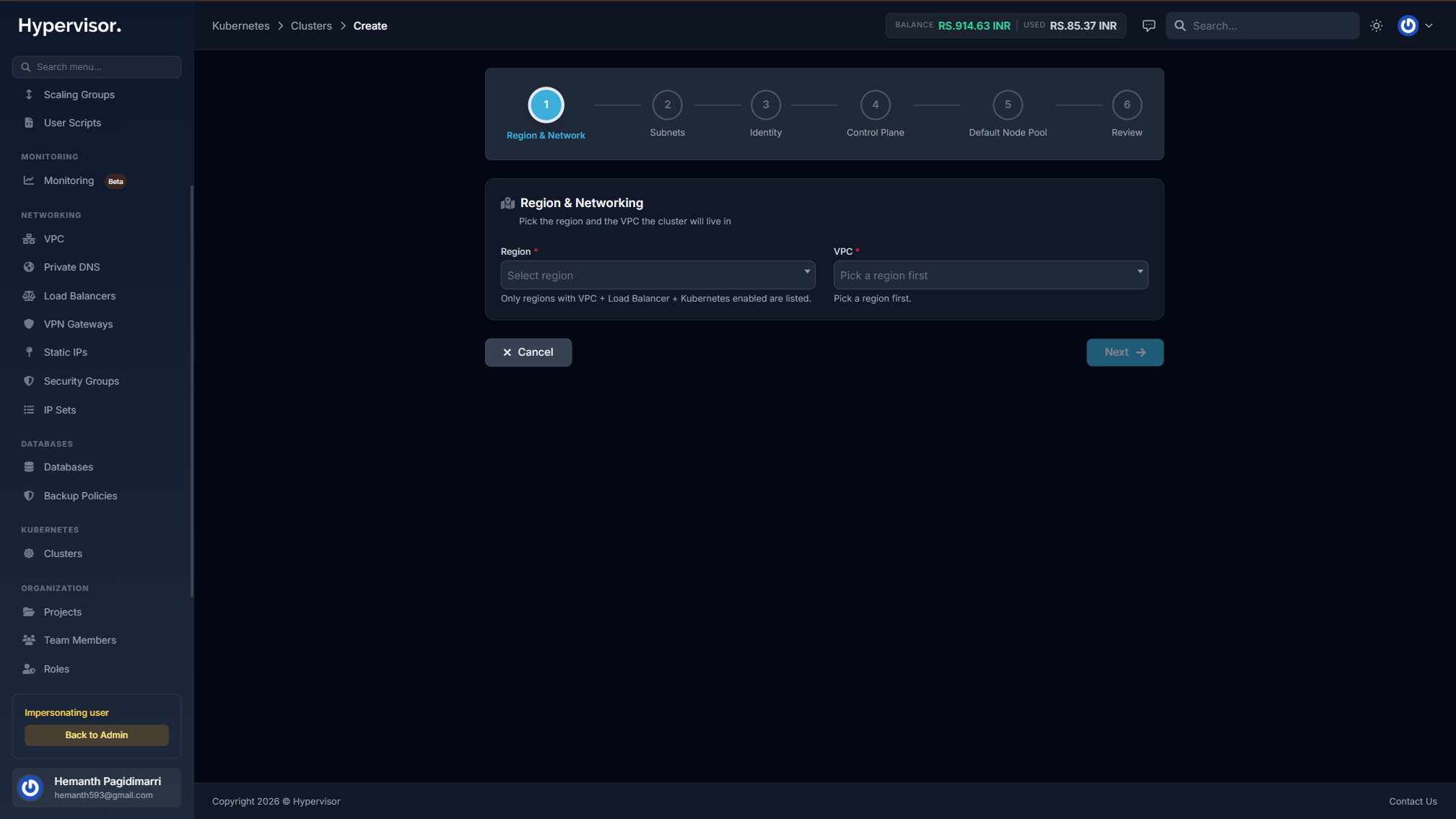
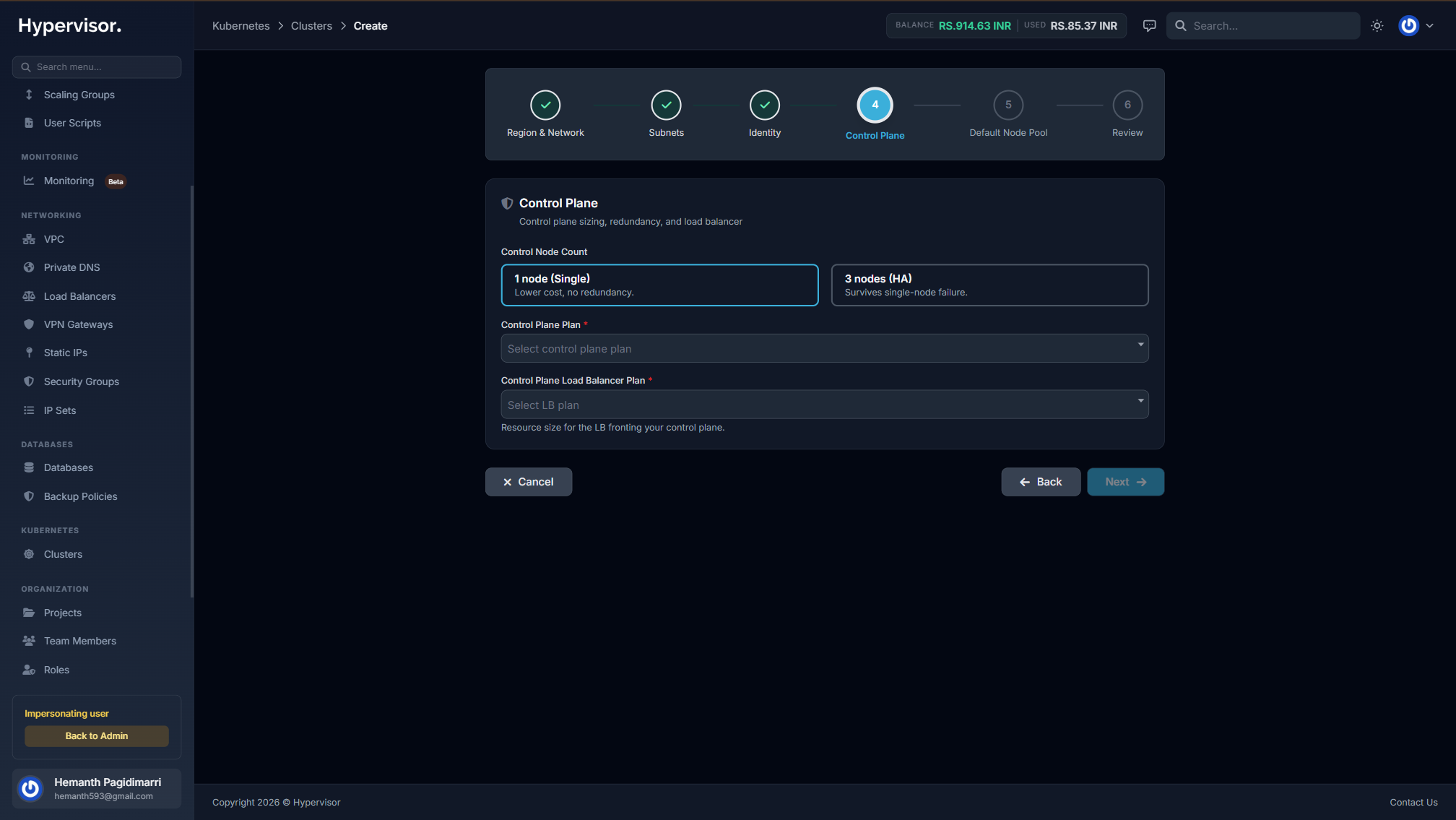
Launch a cluster in minutes from a six-step wizard
Pick a region, plug into one of your VPCs, choose Single or HA control plane, set worker count and autoscaler bounds, hit create. Provisioning finishes in 5–12 minutes with a live progress overlay.
Multi-region
Each cluster lives in a region of your choice. Deploy in one region or operate clusters across many regions from the same panel.
VPC-native
Clusters run inside one of your VPCs. Control plane nodes sit in private subnets; workers can live in private or public subnets.
Curated versions
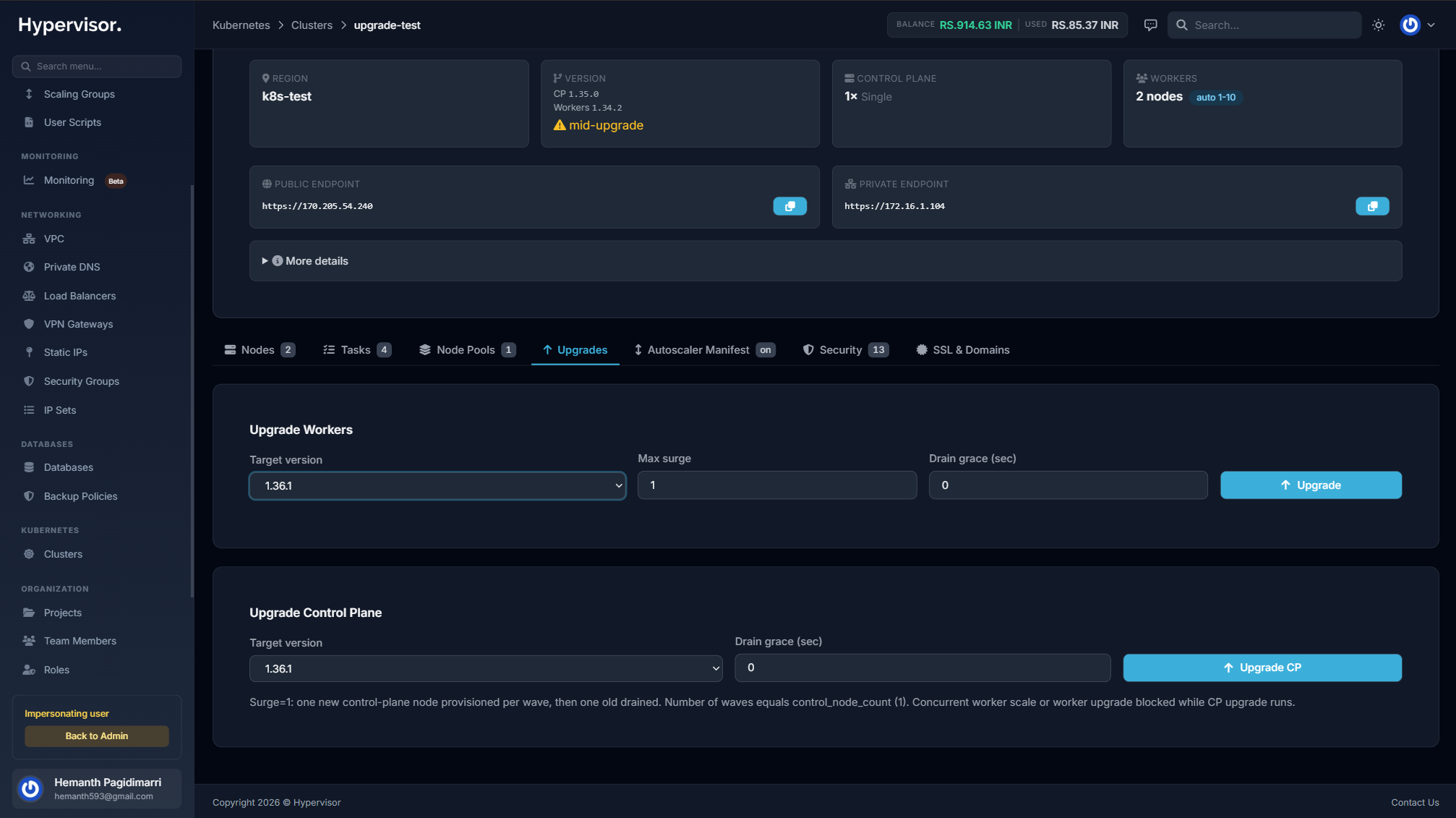
Choose from an admin-managed catalogue of supported Kubernetes versions. Each version ships with vetted container images and tested upgrade paths.
Live progress
A real-time overlay shows the current bootstrap phase with optional log expansion. No more guessing whether provisioning is stuck.